Simple Http Server(SHS)是Linux下一个超轻量级的Http Server,可以接受用户的静态或动态请求,对于大致了解服务器的工作流程、熟悉HTTP协议及UNIX网络编程有一定帮助。
1. 项目简介
一个简单的开源项目,对于熟悉HTTP协议,服务器的工作流程,特别是UNIX网络编程,有较大的帮助。同时还继续用到了稍复杂的双向管道等进程间通信的知识。
项目结构
- httpd.c: 服务器端主程序,用于建立一个http Server。
- simpleclient.c: 服务器简易测试程序,一个客户端,用于测试服务器的连通。
- makefile: 描述了整个工程的编译、连接等规则。
- README.md: 描述了项目的安装及使用方法。
- httpdocs: 服务器本地文件夹,包含一些网页和CGI脚本。
2. 核心文件: httpd.c
核心函数
- main: 主要用于创建并监听服务器连接,当有连接到来时,创建线程对其套结字进行处理。
- startup: 主要用于初始化httpd服务,包括socket、bind、listen等。
- accept_request: 主要用于处理从监听套结字上获得的一个HTTP请求。
- get_line: 主要用于读取套结字的一行,把/r/n或/n等结尾都统一为换行结束符/n。
- server_file: 主要用于处理静态请求,调用cat函数把服务器文件返回给浏览器。
- execute_cgi: 主要用于处理动态请求,运行CGI处理程序。
- headers: 把HTTP响应的头部写到套结字中。
- cat: 读取服务器上某个文件并写到套结字中。
3. 细节实现
3.1 get_line函数
在Windows和Linux中有不同的结束符,有时候会带来很麻烦的问题,通过使用自定义的getline函数,无论结尾是什么结束符,都将其转换成‘\n’。
常见问题
Windows中的结束符为“\r\n”,‘\r‘(回车符)代表每次光标移动到本行的行首位置处,‘\n’(换行符)代表每次光标移动到下一行的行首位置处;在Linux中的结束符为‘\n’;在Mac中的结束符为‘\r‘。在Linux中遇到‘\n’会进行回车+换行的操作,回车符反而只会作为控制字符(“^M”)显示,不会发生回车操作;而Windows中要“\r\n”才会回车+换行,缺少一个控制符或者顺序不对都不能正确的另起一行。
3.2 unimplement函数
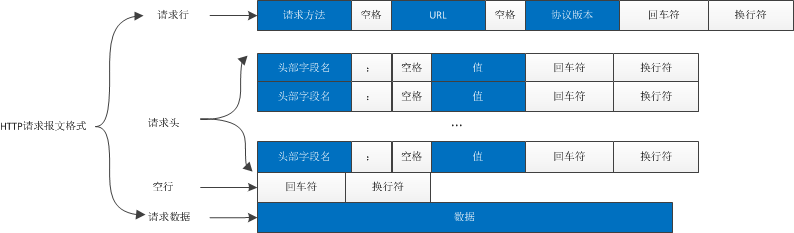
httpd.c中还有不少类似的函数,如not_found、headers、cannot_execute、bad_request等,它们都是根据HTTP的请求,模拟的HTTP响应。HTTP请求和响应的具体报文格式可以参照我的博文HTTP协议。
3.3 stat函数
- 头文件:
#include <stat.h> #include <unistd.h>- 函数声明:
int stat(const char *file_name,struct stat *buf)- 函数功能: 通过文件名filename获取文件信息,并保存在buf所指的结构体stat中
参数结构stat定义如下:
1 | struct stat{ |
| 错误代码 | 说明 |
|---|---|
| ENOENT | 参数file_name指定的文件不存在 |
| ENOTDIR | 路径中的目录存在但却非真正的目录 |
| ELOOP | 欲打开的文件有过多符号连接问题,上限为16符号连接 |
| EFAULT | 参数buf为无效指针,指向无法存在的内存空间 |
| EACCESS | 存取文件时被拒绝 |
| ENOMEM | 核心内存不足 |
| ENAMETOOLONG | 参数file_name的路径名称太长 |
| st_mode | 值 | 说明 |
|---|---|---|
| S_IFMT | 0170000 | 文件类型选择 |
| S_IFSOCK | 0140000 | socket |
| S_IFLNK | 0120000 | 符号连接 |
| S_IFREG | 0100000 | 一般文件 |
| S_IFBLK | 0060000 | 区块装置 |
| S_IFDIR | 0040000 | 目录 |
| S_IFCHR | 0020000 | 字符装置 |
| S_IFIFO | 0010000 | 先进先出 |
| S_ISUID | 04000 | 文件的SUID |
| S_ISGID | 02000 | 文件的SGID |
| S_ISVTX | 01000 | 文件的sticky位 |
| S_IRUSR(S_IREAD) | 00400 | 文件所有者具可读取权限 |
| S_IWUSR(S_IWRITE) | 00200 | 文件所有者具可写入权限 |
| S_IXUSR(S_IEXEC) | 00100 | 文件所有者具可执行权限 |
| S_IRGRP | 00040 | 用户组具可读取权限 |
| S_IWGRP | 00020 | 用户组具可写入权限 |
| S_IXGRP | 00010 | 用户组具可执行权限 |
| S_IROTH | 00004 | 其他用户具可读取权限 |
| S_IWOTH | 00002 | 其他用户具可写入权限 |
| S_IXOTH | 00001 | 其他用户具可执行权限 |
通过该函数对文件权限进行判断,判断是否具有可执行权限,如果有,就调用函数execute_cgi执行动态脚本,否则,调用函数server_file返回静态页面。
注意事项
相关的cgi文件要增加可执行权限,否则不会被当作可执行文件。
3.4 execute_cgi函数
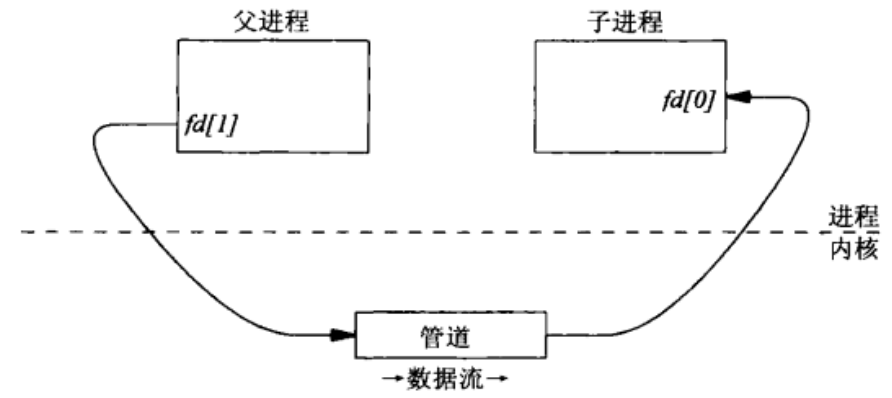
当遇到服务器端的POST请求以及GET请求带有?参数时,用此函数来执行动态脚本。以显示颜色为例。打开网页,连接服务器后,输入颜色,点击“Submit”后,传递HTTP的POST请求到服务器,服务器解析后得到method、path。将这些参数传递给该函数,创建子进程,建立管道。从客户浏览器传入的POST数据,由父进程写入管道cgi_input[1];子进程从STDIN接受数据,即管道cgi_input[0],负责设置环境变量,并执行execl函数,结果将被传入STDOUT,即管道cgi_output[1],父进程从cgi_output[0]中读取相关信息返回给客户浏览器。这里需要使用一个双向数据流管道,如下图所示。
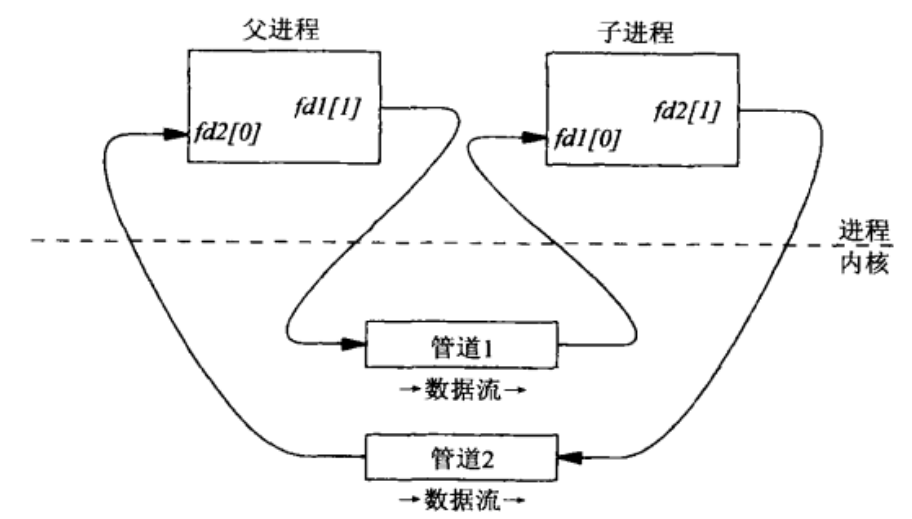
扩展介绍
CGI程序的特点是通过标准输入(stdin)和环境变量(可以理解成有两个传递数据的途径,二者相辅相成,其实跟请求方法是get或post也相关)来得到服务器的信息,并通过标准输出(stdout)向服务器输出信息。
4. 调试
有了前一个项目的GDB调试经验,这个调试起来较为方便,详细的GDB操作可以查看上一个项目的博文。这里是先开启服务器再进行调试。
可以使用如下命令找到httpd的进程号并开启GDB调试:
1 | ps aux | grep httpd |
调试问题
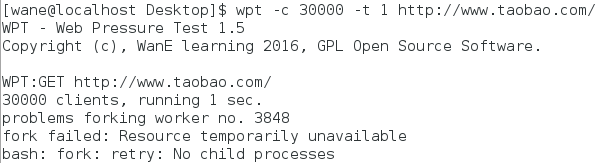
在创建线程时,有时会自动的创建两个线程,没有找到原因,继续运行时,最后都以SIGPIPE信号终止。信号的原因:连接建立,若某一端关闭连接,而另一端仍然向它写数据,第一次写数据后会收到RST响应,此后再写数据,内核将向进程发出SIGPIPE信号,通知进程此连接已经断开。而SIGPIPE信号的默认处理是终止程序,导致上述问题的发生。
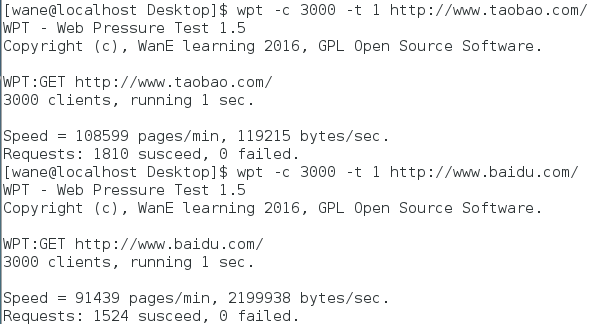
测试结果
- 显示颜色


- 显示服务器时间


5. 完善与维护
完成后,将项目上传至Github维护。
项目地址:Simple Http Server
6. 总结
这是自己学习的第二个项目,以之前的HTTP协议的知识为基础,实践了一下它在Http Server中的应用,了解了服务器的工作流程,但多线程及IPC相关的知识还有待加强。
下面一阶段要不断的看书充电,把没有解决的问题继续解决,以这两个项目为实战参考。See you in next program!